Conductrics takes privacy seriously. Conductrics AB Testing has been developed in conformance with Privacy by Design principles in order to give our clients the privacy options they need. This is important for: 1) maintaining customer trust by safeguarding their privacy; and 2) in order to comply with privacy regulations that require systems to be designed with default behaviors that provide privacy protections.
For example, Article 25 of the GDPR requires “Data protection by design and by default” and explicitly proposes the use of pseudonymization as a means to comply with the overarching data minimization principle. Technology should be designed in such a way that by default the scope of data collected is limited to “only personal data which are necessary for each specific purpose of the processing are processed.” In other words, if a task can be performed without the use of an additional bit of data, then, by default, that extra bit of data should not be collected or stored.
With Conductrics, clients are able to run AB Tests without the need to collect or store AB Test data that is linked directly to individuals, or associated with any other information about them that is not explicitly required to perform the test. Out of the box, Conductrics collects AND stores data using data minimization and aggregation methods.
This is unlike other experimentation systems that follow what can be called an identity-centric strategy. This approach links all events, experimental treatments, sales etc., back to an individual, usually via some sort of visitor Id.
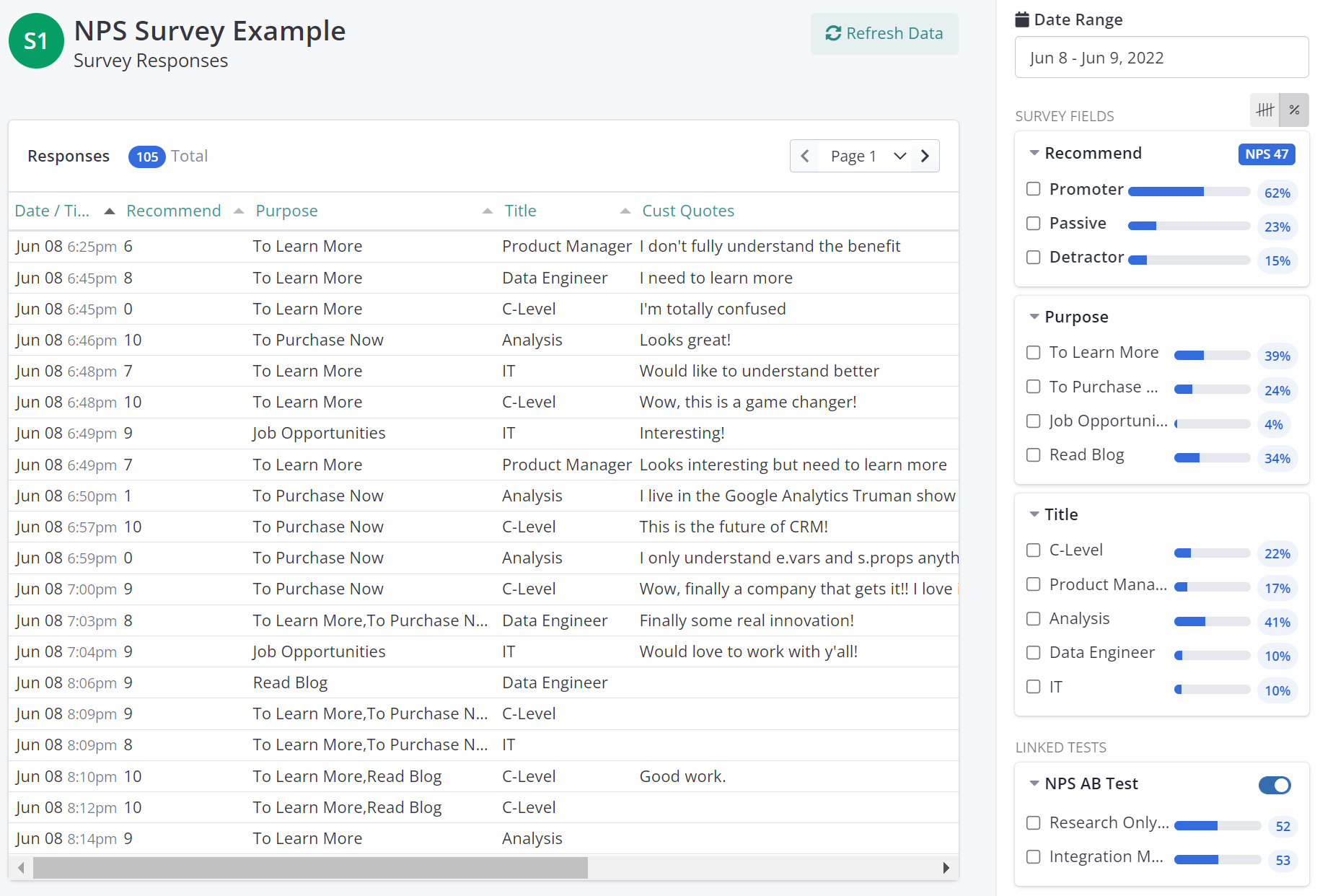
For clarity, lets look at an example. In the table below there are three experiments running; Exp1, Exp2, and Exp3. Each experiment is joined back to a customer such that there is a table (or logical relationship) that links each experiment and the assigned treatment back to a visitor.

While this level of detail can be useful for various ad hoc statistical analysis, it also means that the experimentation system has less privacy control since all the information about a person is linked back to each experiment.
One can use pseudonymization, where the explicitly identifiable information (the Name, Email, and often Cust ID) can be removed from the table. However, what many fail to realize is that even if we remove those fields but keep all of the other associations at the same individual level, the remaining data often still contains more information than required and might be at a higher risk of being able to leak personal information about individuals.
Happily, it turns out that for most standard experiments there is no need to collect or store data at the individual level to run the required statistical procedures for AB Tests – or even for certain versions of regression analysis useful for things like AB Test interaction checks. Instead of collecting, linking, and storing experiment data per individual, Conductrics collects and stores experiment data that we both de-identify AND aggregate AS IT IS COLLECTED. This makes it possible to both collect and store the experimental data in an aggregate form such that the experimentation platform NEVER needs to know identifying individual level data.
Privacy by Design: Data Minimization and Aggregation
In the context of privacy engineering, network centricity (“the extent to which personal information remains local to the client”) is considered a key quality attribute in the Privacy by Design process. This can be illustrated by contrasting so-called “global privacy” with “local privacy”.
In the global privacy approach identifiable, non minimized data is collected and stored, but only by a trusted curator. For example, the US Gov’t collects census data about US citizens. The US Census Bureau acts as the trusted curator, with access to all of the personal information collected by the census. However, before the Census Bureau releases any data publicly, it applies de-identification and data minimization procedures to help ensure privacy.
Local privacy, by contrast, is a stronger form of privacy protection because data is de-identified and minimized as it is collected and stored. This removes the need for a trusted curator. Conductrics is designed to allow for a local privacy approach by default, such that Conductrics only collects and stores data in its minimized form.
In the process of doing so, Conductrics is also respecting the key privacy engineering objective of dissociability – a key pillar of the NIST Privacy Framework.
How does this data collection work?
Rather than link all of the experiments back to a common user in a customer table / relational model above, Conductrics stores each experiment in its own separate data table. For simple AB Tests each of these tables in turn only need to record three primary values for each treatment in the experiment: 1) The count of enrolments (the number of users per treatment); 2) The total value of the conversions or goals for each treatment; and 3) the total value of the square of each conversion value. Let’s take a look at a few examples to make this clear. At the start of the experiment the AB Test’s data table is empty.
AB Test 1
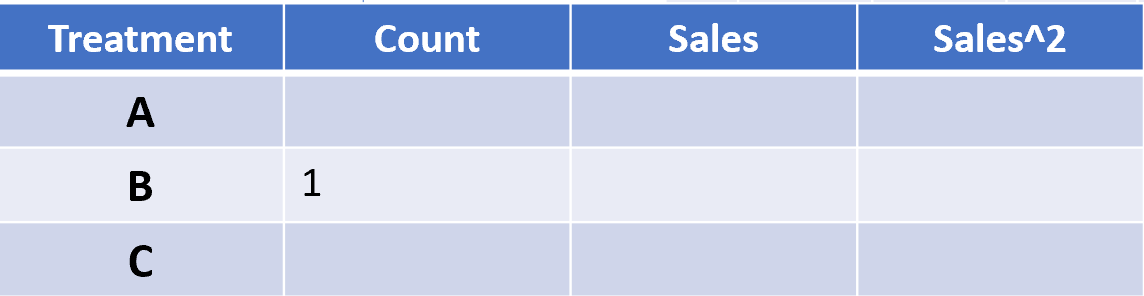
As users are assigned to treatments, Conductrics receives telemetry from each user’s client (browser) with only the information needed to update the data table above. For example, say a customer on the client website gets assigned to the ‘B’ treatment in the AB Test. A message is sent to Conductrics (optionally, the messages can be first passed to the organization’s own servers via Conductrics Privacy Server for even more privacy control).
This message looks something like ‘ABTest1:B’ and the AB Test’s data table in Conductrics is updated as follows:
If the user then purchases the product attached to the test, the following message is sent ‘ABTest1:B:10’. Conductrics interprets this as a message to update the Sales field for Treatment B by $10 and the Sales^2 field by 100 (since 10^2=100). Notice that no visitor identifier is needed to make this update (Note: The actual system is a bit more complex, ensuring that the Sales^2 records properly account for multiple conversion events per user, but this is the general idea.)
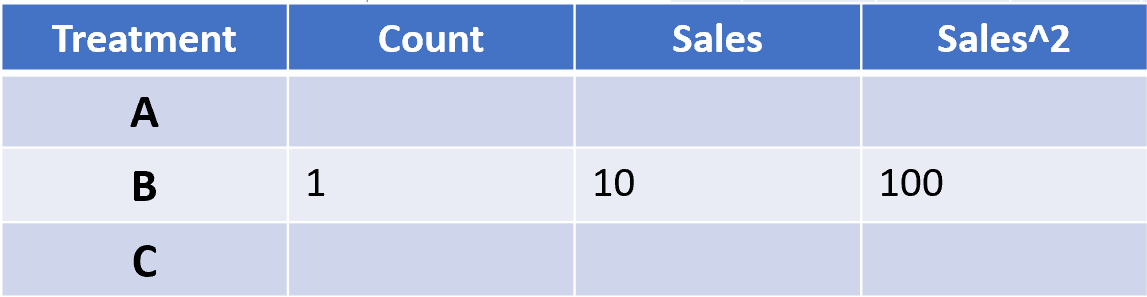
As new users enter the test and purchase, the AB Test’s data table accumulates and stores the data in its minimized form. So by the end of our experiment we might have a data table that looks like this:
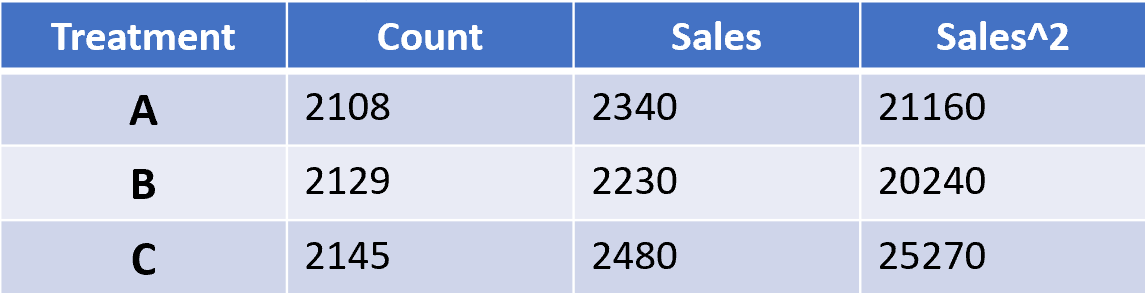
A nice property of this is that not only has the data been collected and stored in a minimized form for increased privacy, but it is also in a form that is much more efficient to calculate statistical tests. This is because most of the required summation calculations that are required for things like t-tests and covariance tables have already been done.
Interestingly we are not limited to just simple AB Tests. We can extend this approach to include additional segment data. For example if we wanted to analyze the AB Test data based on segments – say built on customer value levels; Low (L) ,Medium (M),and High (H), the data would be stored as follows.
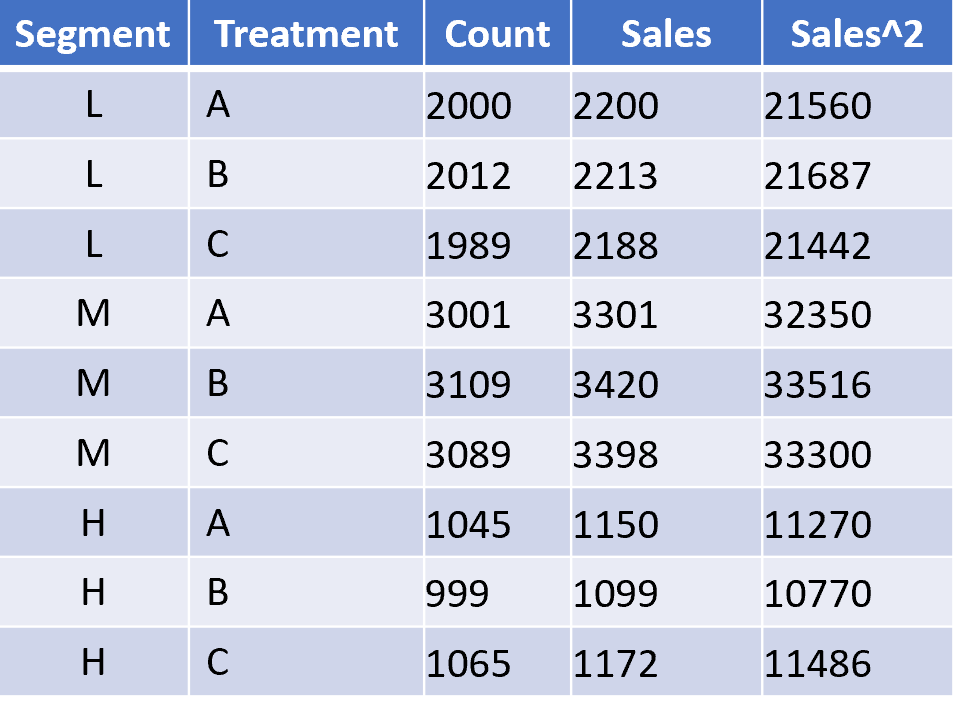
There is of course no need to limit the number of segments to just one. We can have any number of combinations of segments. Each combination is known as an equivalence class. As we increase the segment detail of each equivalence classes we also increase the number (based on the cardinality of the segment combinations).
So as the number of classes increase, there is an associated increase the possibility of identifying or leaking information about persons entered into a test. To balance this, Conductrics collection of user traits/segments follows from ideas of K-Anonymization, a de-identification technique based on the idea that the collected user data should have groups of at least K other users who look exactly the same. Depending on each experiment’s context and sensitivity, Conductrics can either store each user segment/trait group in its own separate data table, effectively keeping the segment data de-linked, or store the data at the segment combination level.
This gives our clients the ability to decide how strict they need to be with how much the data is aggregated. In the near future Conductrics will be adding reporting tools that will allow clients to query each experiment to help manage and ensure that data across all of their experiments is stored at the appropriate aggregation level.
What about the Stats?
While statistics can be very complicated, calculations behind most of the common approaches for AB Testing ( e.g Welch t-tests. z-tests, Chi-Square, F-Tests, etc.) under the hood are really mostly just a bunch of summing and squaring of numbers.
For example, the mean (average) value for each treatment is just the sum of Sales divided by the number of enrollments for each treatment. By dividing the sales column by the count column for each treatment we can calculate the average conversion value per treatment.
The calculations for the variance and standard errors are a bit more complicated but they use a version of the following general form for the variance which uses the aggregated sum of squares data field (where each value is squared first then those squared values are all added up):
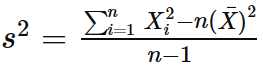
It turns out that this approach can be generalized to the multivariate case, and using similar logic, we can also run regressions required for MVTs and interaction checks. Technical readers might be interested to notice that the inner product elements of the Gram Matrix for ANOVA/OLS with categorical covariates are just conditional sums that we can pluck from the aggregated data table with minimal additional calculations.
Intentional Data Collection and Use
Of course there are use cases where it is appropriate and necessary to collect more specific, and identifiable information. However, it is often the case that we can answer the very same questions without ever needing to. The main point is rather than collecting, linking, and storing all of the extra information by default just in case it might be useful, we should be intentional for each use case about what is actually needed, and proceed from there.
Lastly, we should note that disassociation methods and data minimization by default are not substitutes for proper privacy policies – perhaps one could argue that alternative approaches, such as differential privacy might be, but generally the types of methods discussed here are not). Rather, privacy engineering is a tool that sits alongside required privacy and legal compliance policies and contracts.
If you would like to learn more about Conductrics please reach out here.