
I was talking with Kelly Wortham during her excellent A/B testing webinar series. During the conversation, one of the attendees asked if they just wanted to pick between A and B, did they really need to run standard significance tests at a 90% or 95% confidence levels?
The simple answer is no. In fact, in certain cases, you can avoid dealing with p-values (or priors and posteriors) altogether and just pick the option with the highest conversion rate. Even more interesting, at least to me, is that simple approach can be viewed as either form of classical hypothesis testing or as an epsilon- first solution to the multi-arm bandit problem.
Before we get into our simple bandit trick, it might be helpful to first revisit a few important concepts that underpin why we are running tests in the first place.
The reason we run experiments is to help determine how different marketing interventions will affect the user experience. The more data we collect, the more information we have, which reduces our uncertainty about the effectiveness of each possible intervention. Since data collection is costly, the question that always comes up is ‘how much data do I really need to collect?’
In a way, every time we run an experiment, we are trying to balance the following: 1) the cost of making a Type 1 error; 2) the cost of making a Type 2 error; and 3) the cost of the data collection to reduce our risk of making either of these errors.
To help answer this question, I find it helpful to organize optimization problems into two high level classes of problems:
1) Do No Harm
These are problems where there is either:
- an existing process, or customer experience, that the organization is counting on for at least a certain minimum level of performance.
- a direct cost associated with implementing a change.
For example, while it would be great if we could increase conversions from an existing check out process, it may be catastrophic if we accidentally reduced the conversion rate. Or, perhaps we want to use data for targeting offers, but there is a real direct cost we have to pay in order to use the targeting data. If it turns out that there is no benefit to the targeting, we will incur the additional data cost without any upside, resulting in a net loss.
So, for the ‘Do No Harm’ type of problem we want to be pretty sure that if we do make a change, it will make things better and make things worse. For these problems we want to stay the current course unless we have strong evidence to take an alternative action.
2) Go For It
In the ‘Go For It’ type of problem there often is no existing course to follow. Here we are selecting between two or more novel choices AND we have symmetric costs, or loss, if we make a Type I error (reviewed below).
A good example is headline optimization for news articles. Each news article is, by definition, novel, as are the associated headlines. Assuming that one has already decided to run headline optimization (which is itself a ‘Do No Harm’ question), there is no added cost, or risk to selecting one or the other headlines when there is no real difference in the conversion metric between them. The objective of this type of problem is to maximize the chance of finding the best option, if there is one. If there isn’t one, then there is no cost or risk to just randomly select between them (since they perform equally as well and have the same cost to deploy). As it turns out, Go For It problems are also good candidates for Bandit methods.
State of the World
Now that we have our two types of problems defined, we can ask under what situations we might find ourselves when we finally make a decision (i.e. select ‘A’ or ‘B’). There are two possible states of the world when we make our decisions:
-
There isn’t the expected effect/difference between the options
-
There is the expected effect/difference between the options
It is important to keep in mind that in almost all cases we won’t be entirely certain what the true state of the world is, even after we run our experiment (you can thank David Hume for this). This is where our two error types, Type I and Type II come into play. You can think of these two error types as really just two situations where our Beliefs about the world are not consistent with the true state of the world.
A Type I error is when we pick the alternative option (the ‘B’ option), because we mistakenly believe the true state of the world is ‘Effect’. Alternatively, a Type II error is when we pick ‘A’ (stay the course), thinking that there is no effect, when the true state of the world is ‘Effect’.
The difference between the ‘Do No Harm’ and ‘Go For It’ problems is in how costly it is to make a Type I error.
The table below is the payoff matrix for each error for ‘Do No Harm’ problems
| Decision | Expected Effect | No Expected Effect |
| Pick A | Opportunity Costs | No Cost |
| Pick B | No Opportunity Cost | Cost |
Notice, that if we pick B when there is no effect, we make a Type I error and suffer a cost. Now lets look at the payoff table for the ‘Go For It’ problem.
| Decision | Expected Effect | No Expected Effect |
| Pick A | Opportunity Costs | No Cost |
| Pick B | No Opportunity Cost | No Cost |
Notice that the payoff tables for Do No Harm and Go For It are the same when the true state of the world is that there is an effect. But, they differ when there is no effect. When there is no effect, there is NO relative cost in selecting either A or B.
Why is this way of thinking about optimization problems useful?
Because this can help with what type of approach to take based on the problem.
In the Do No Harm problem we need to be mindful about Type I errors, because they are costly, so we need to factor in the risk of making them when we design our experiments. Managing this risk is exactly what classical hypothesis testing does.
That is why for ‘Do No Harm’ problems, it is best practice to run a classic, robust, AB Test. This is because we care more about minimizing our risk of doing harm (the cost of Type I error) than any benefit we might get from rushing through the experiment (cost of information).
However, it also means that if we have a ‘Go For It’ problem, if there is no effect, we don’t really care how we make our selections. Picking randomly when there is no effect is fine, as each of the options have the same value. It is this case where our simple test of just picking the highest value option makes sense.
Go For It: Tests with no P-Values
Finally we can get to the simple bandit using the our sample size calculators. This approach guarantees that if there is a true difference of the minimum discernible effect (MDE), or larger, one will choose the better-performing arm based on desired power. So if the power is 0.95, then the bandit will pick the best option 95% of the time IF there is an option that is MDE or greater better than the others.
Here are the steps:
1) Calculate the sample size using the desired power, desired MDE, and an alpha of 0.5 (not 0.05, but 0.5).
2) Collect the data
3) Pick whichever option has the highest raw conversion value. If a tie, flip a coin.
Ah, I hear you asking ‘What’s the deal with alpha, why are we selecting it to be 0.5?’ Here is the trick. We want to select randomly when there is no effect. By setting alpha to 0.5, this null test will reject the null 50% of the time when null is true (no effect).Lets go through a simple example to make this clear.
Let’s say your landing page tends to have a conversion rate of around 4%. You are trying out a new alternative offer, and a meaningful improvement for your business would a lift to a 5% conversion rate. So the minimum detectable effect (MDE) for the test is 0.01 (1%).
You then estimate the sample size needed to find the MDE if it exists. Normally, we pick an alpha of 0.05 , but now we are instead going to use an alpha of 0.5. The final step is to pick the power of the test, lets use a good one, 0.95 (often folks pick, 0.8, but for this case we will use 0.95).
You can use now use your favorite sample size calculator (for Conductrics users this is part of the set up work flow).
If you use R, this will look something like:
power.prop.test(n = NULL, p1 = 0.04, p2 = 0.05, sig.level = 0.5, power = .95,
alternative =”one.sided”, strict = FALSE)
This gives us a sample size of 2,324 per option, or 4,648 in total. If we were to run this as a standard A/B test with a confidence of level of 95% (alpha=0.05) would need to have almost four times the traffic, 9,299 per options, or 18,598 in total.
The following is a simulation of 100K experiments, where each experiment selected each arm 2,324 times. The conversion rate for B was set to 5% and 4% for A. The chart below plots the difference in the conversion rates between A and B for each simulation. Not surprisingly, the simulation’s results are centered on the true difference of 0.01. The main thing to notice is that if we pick the option with the highest conversion rate, we pick B 95% of the time, which is exactly the power we used to calculate the sample size!
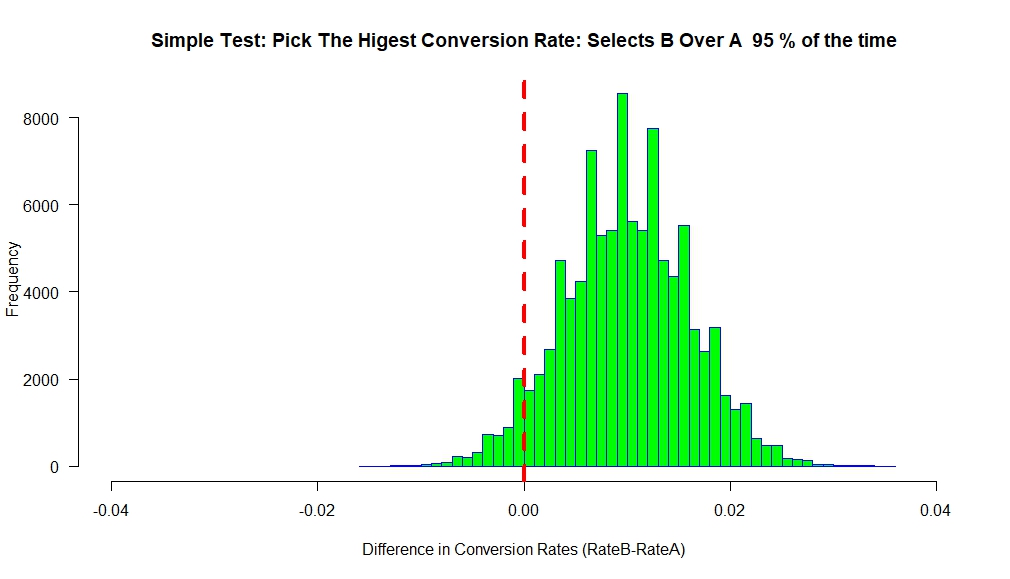
Notice also no p-values, just a simple rule to pick whatever is performing best and we get postive results the expected 95% of the time. Plus it only used about one fourth of the data to reach that level power vs a standand A/B test.
Now lets see what our simulation looks like when both A and B have the same conversion rate of 4% (Null is true).
Notice that the difference between A and B is centered at ‘0’ over the simulation, as we would expect. Using our simple decision rule, we pick B 50% of the time and A 50% of the time.
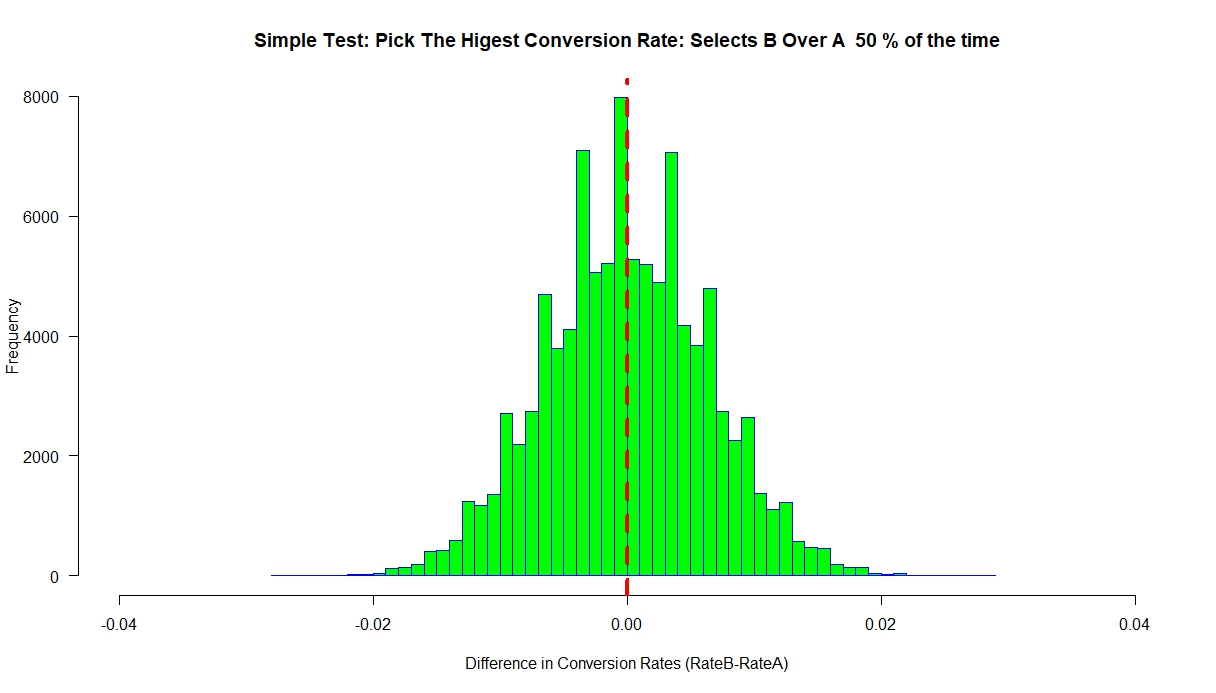
Now, if we had a Do No Harm problem, this would be a terrible way to make our decisions because half the time we would select B over A and incur a cost. So you still have to do the work and determine your relative costs around data collection, Type 1, Type II errors.
While I was doing some research on this, I came across Georgi Z. Georgiev’s Analytics toolkit. It has a nice calculator that lets you select your optimal risk balance. He also touches on running tests with an alpha of 0.5.
What about Bandits?
As I mentioned above, we can also think of our Go For It problems as a bandit. Bandit solutions that first randomly collect data and then apply the ‘winner’ we call epsilon-first. Epsilon stands for how much of your time you spend during the data collection phase. In this way of looking at the problem, the sample size output from our sample size calculation (based on MDE and Power), is our Epsilon – how long we let the bandit collect data in order to learn.
What is interesting is that, at least in the two-option case, this easy method gives us roughly the same results as an adaptive Bandit method would. Google has a nice blog post on Thompson Sampling, which is a near-optimal way to dynamically solve bandit problems. We also use Thompson Sampling here at Conductrics, so I thought it might be interesting to compare their results on the same problem.
In one example, Google ran a Bandit with two arms, one with a 4% conversion rate, and the other with a 5% conversion rate – just like our example. While they show the Bandit performing well, needing only an average of 5,120 samples, you will note that that is still slightly higher than the fixed amount we used (4,648 samples) in our super simple method.
This doesn’t mean that we don’t ever want to use Thompson Sampling for bandits. As we increase the number of possible options, and many of those options are strictly worse than the others, running Thompson Sampling or other adaptive design can make sense. That said, by using a multiple comparison adjustments, like the Šidák correction, one can include K>2 arms in the simple epsilon-first method and still get Type 2 power guarantees as well as other advantages in terms of robustness we might explore in a later post. But, as I mentioned, this becomes a less competitive approach if there are many arms, and some of those arms are much worse than the MDE.
The weeds
You may be hesitant to believe that such a simple rule can accurately help detect an effect. I checked in with Alex Damour, the Neyman Visiting Assistant Professor over at UC Berkeley and he pointed out that this simple approach is equivalent to running a standard t-test of the following form. From Alex:
“Find N such that P(meanA-meanB < 0 | A = B + MDE) < 0.05. This is equal to the N needed to have 95% power for a one-sided test with alpha = 0.5.
Proof: Setting alpha = 0.5 sets the rejection threshold at 0. So a 95% power means that the test statistic is greater than zero 95% of the time under the alternative (A = B + MDE). The test statistic has the same sign as meanA-meanB. So, at this sample size, P(meanA – meanB > 0 | A = B + MDE) = 0.95.”
To help visualize this, we can rerun our simulation, but run our test using the above formulation.
Under the Null (No Effect), we have the following result:
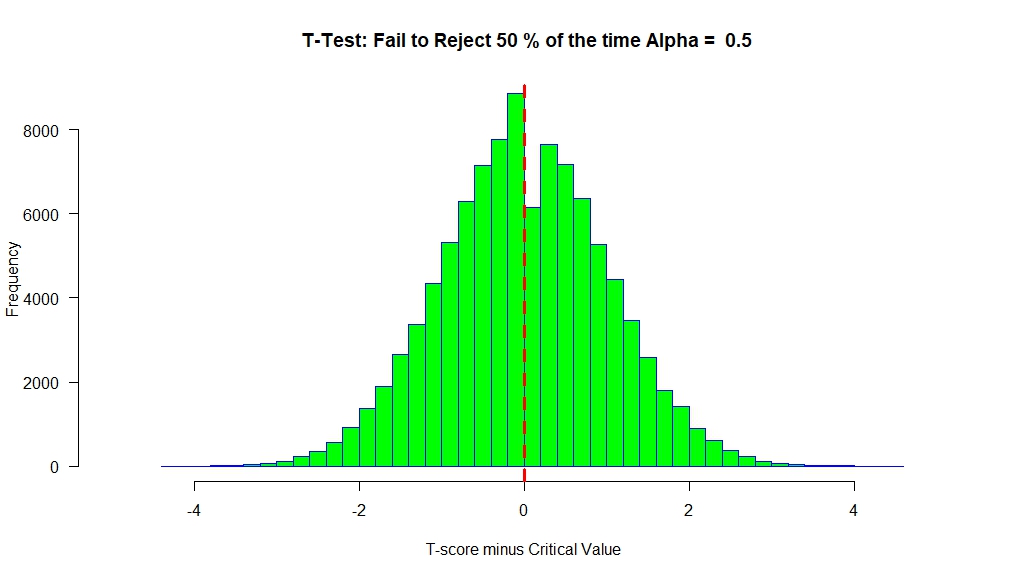
We see that the T-scores are centered around ‘0’. At alpha=0.5, the critical value will be ‘0’. So any T-score greater than ‘0’ will lead to a ‘Rejection’ of the null.
If there is an effect, then we get the following result.
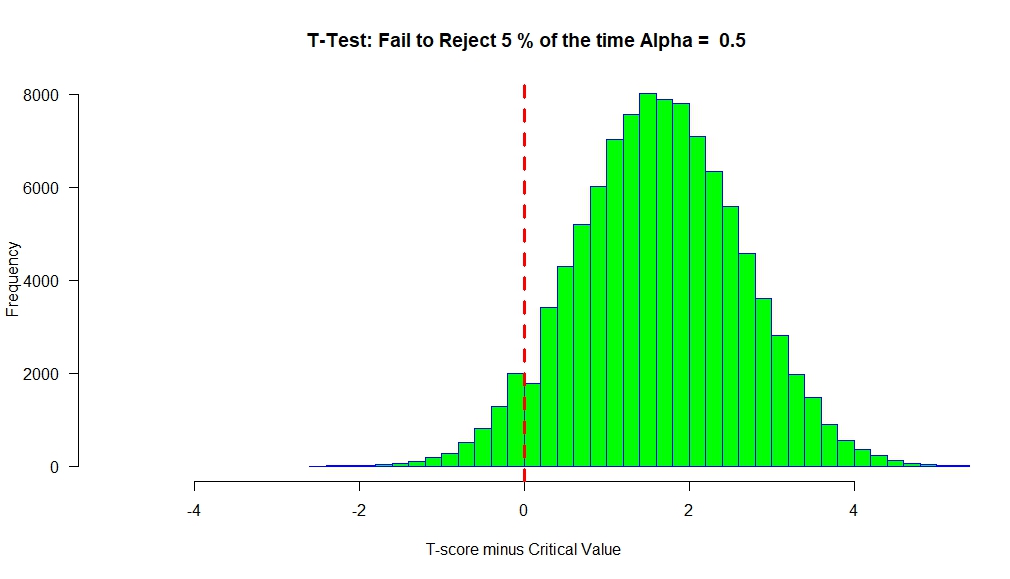
Our distribution of T-scores is shifted to the right, such that only 5% of them (on average) are below ‘0’.
A few final thoughts
Interestingly, at least to me, is that the alpha=0.5 way to solve the ‘Go For It’ problems straddles two of the main approaches in our optimization toolkit. Depending on how you look at it, it can be seen as either: 1) A standard t-test (albeit one with the critical value set to ‘0’); or 2) as an epsilon-first approach to solve a multi-arm bandit.
Looking at it this way, the ‘Go For It’ way of thinking about optimization problems can help bridge our understanding between the two primary ways of solving our optimization problems. It also hints that, as one moves away from Go For It into Do No Harm (higher Type 1 costs), perhaps classic, robust hypothesis testing is the best approach. As we move toward Go For It, one might want to rethink the problem as a multi-armed bandit.
Have fun, don’t get discouraged, and remember optimization is HARD – but that is what makes all the effort required to learn worth it!



