

Multi-armed bandits, Bayesian statistics, machine learning, AI, predictive targeting blah blah blah. So many technical terms, morphing into buzz words, that it gets confusing to understand what is going on when using these methods for digital optimization. Hopefully this post will give you a basic idea of how adaptive learning works, at least here at Conductrics, without getting stuck in the AI hype rabbit hole.
Forget Dice, Let’s Play Roulette
tl;dr Select higher value options more often than lower valued ones, and adjust the relative frequency depending on the user.
What is the difference between basic AB Testing and Adaptive selection? Adaptive selection differs from AB Test selection by dynamically weighing the probability of selection to favor the higher value decision options. This has the effect of selecting options with higher predicted values more often, and selecting the lower values options less often. In AB Testing each experience has an equal chance to be selected (or if not equal, the chance of selection has been fixed by the test designer).
To help visualize this, imagine a roulette wheel. Under a “fair” random policy, the roulette wheel assigns an equal area to each option. For three options, our roulette wheel looks like this:

We spin the roulette wheel and select the option that the wheel stops on. Because each option has an equal share of the wheel, each option has an equal chance to be selected from each spin.
In adaptive/predictive mode, however, Conductrics increases the probability of selecting the options that have higher predicted conversion values, and lowers the probability of options with lower predicted conversion values. This is equivalent to Conductrics constructing a biased roulette wheel to spin for the selections. For example, the roulette wheel below is biased.

If we were to spin this wheel repeatedly, option ‘A’ would, on average, be selected 67% of the time, option ‘B’ 8%, and option ‘C’ only 25%.
Of course, this begs the question, ‘how does Conductrics decide how to weight each option?’
From Bayesian AB Testing to Bandits: How Conductrics calculates the probabilities
Conductrics uses a modified version of Thompson Sampling to make adaptive selections. Thompson sampling is an efficient way to make selections based on the probability that an option is the best one. These selection probabilities are analogues to the areas we assign to the roulette wheel.
Before we take draws using the Thompson sampling method, we first need to construct a probability distribution over the possible conversion values for each option. How do we do that?
For those of you who already know about Bayesian AB Testing, this section will be familiar. Without getting to much into the weeds (we will skip over the use and selection of the prior distribution), we will estimate both the conversion values and a measure of uncertainty (similar to standard error), and construct a probability distribution based on those values. For example, lets say we were using conversion rate as a goal, and we had two options, Grey and Blue, both with a 5% conversion rate. However, for the Grey option we have 3,000 samples, but for the Blue one we only have 300. The predicted conversion rate of the Grey option has less uncertainty than the Blue one because we have 10 times more experience with it.
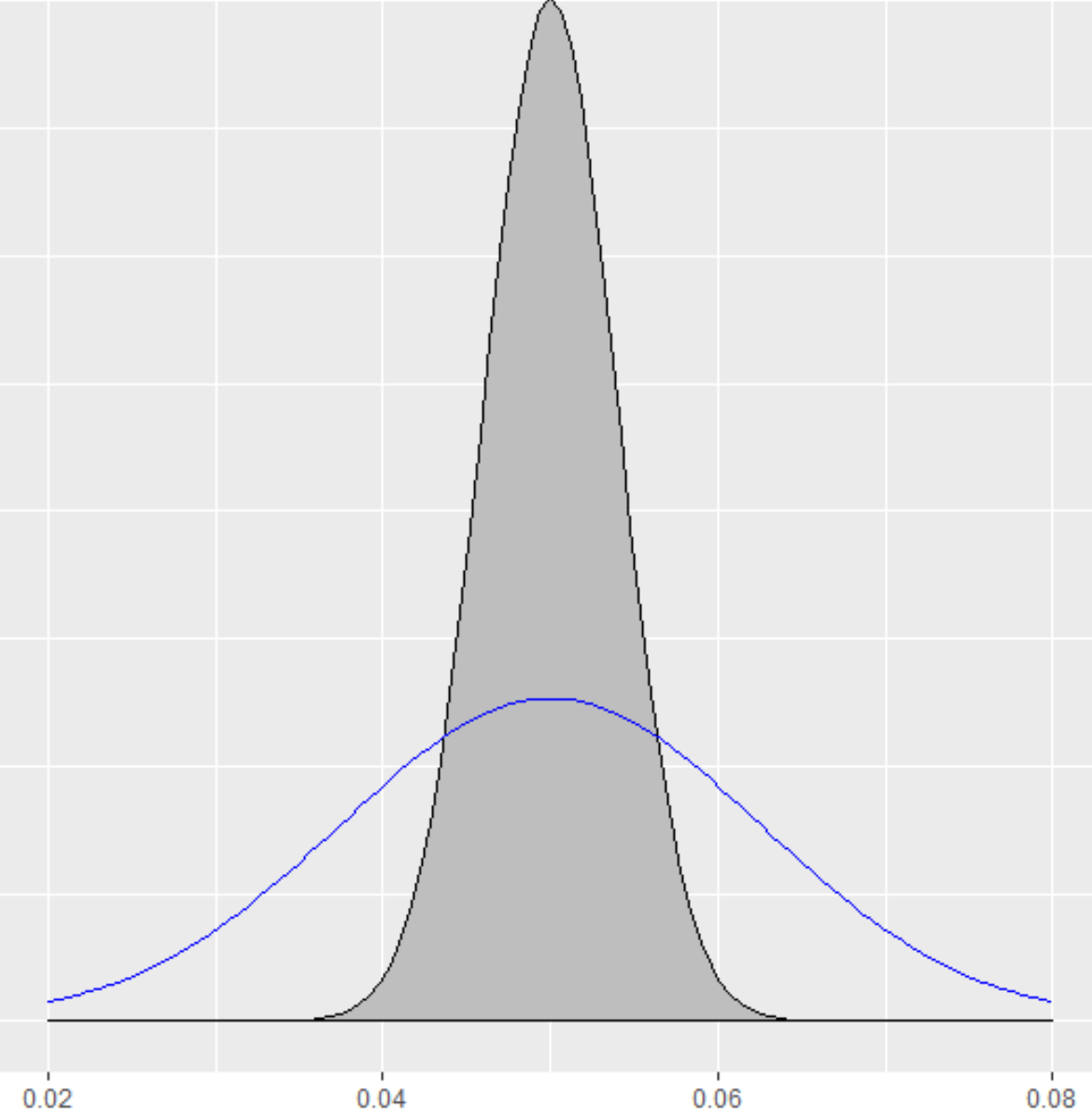
The uncertainty of our estimates are encoded in the width, or spread of our distribution of the predicted values. Notice that the values for Grey are clustered mostly between 4% and 6%, whereas for Blue, while also centered at 5%, has a spread between 2% and 8%.
Now let’s say that rather than having the same average conversion rate, we estimate a conversion rate of 5.5% for our Blue option. Now our distribution for Blue has been shifted slightly to right – centered at 5.5%, rather than at 5%.
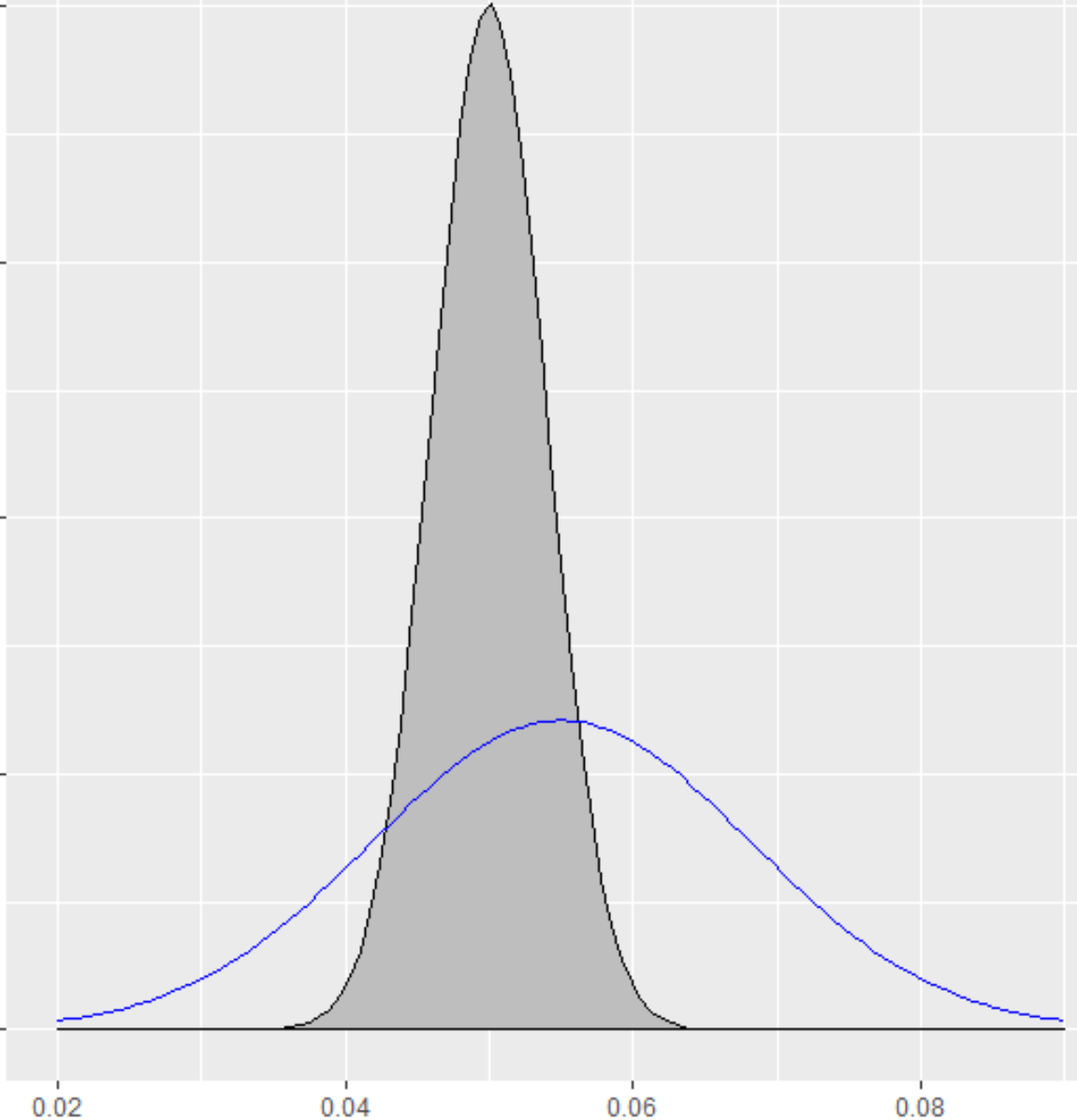
Just by looking at the two distributions, we can see that while Blue has a higher estimated conversion rate, there is so much uncertainty in Blue (as well as some in Grey), that we can’t really be too certain which option really will be the best one going forward.
One simple approach to get an idea of how likely Blue will be better than than Grey, is to take many pairs of random draws from each distribution, compare the results, and then mark how often the result from Blue was greater than Grey.
You can think of Grey and Blue’s conversion rate distributions (those curves in the chart above), as custom random number generators. You can use them just like you would call Excel’s rand() function. Except unlike rand(), where we get back values uniformly distributed between zero and one, calling Dist(Grey) we get back values that are near 0.05, plus or minus a small amount. If we call Dist(Blue), we will get back values near 0.055, plus or minus a larger amount than Grey – reflecting the greater uncertainty in Blue’s predicted conversion rate.
If we called Dist(Grey) and Dist(Blue) 10,000 times, we would get a good idea of how much more likely Blue is better than Grey – in this case Blue comes up higher approx. 62% of the time. We could then conclude, based on the data so far, that Blue has an approximately 62% chance of being the higher valued option and Grey has a 38% chance to be the best option.
Advanced: Priors and AB Testing
If you have experience with Bayesian AB Testing you may be wondering about the selection of the prior distribution. Conductrics uses an approximate empirical Bayesian approach to estimate the prior distributions. The choice of prior can lead to different results than those found in many online testing calculators (which tend to use a uniform prior, whereas Conductrics uses the empirical grand mean for shrinkage/regularization). However, the basic approach is similar to the calculation in many Bayesian AB Testing reports (please see our posts on Shrinkage if you would like to learn more ).
Note: While there is reasonable debate on the best approach for AB Testing, Conductrics recommends the use of error-statistical methods (e.g. t-tests) when the objective is statistical error control (see: Mayo ). Consider applying Bayesian methods, for example the use of posterior distributions discussed in this post, for when the objective is estimation and prediction (of course, regularization and shrinkage aren’t just the purview of Bayesian statistics, so use what you like and works for your problem 🙂 ).
Thompson Sampling and Bandit Selection
Rather than just report on how likely each option is the best one, we can modify this approach to make the selections for each user. This modified approach is called Thompson sampling. The way it works is to take random draws from each of the option’s associated distribution. This is just as we did before, but instead of marking down the option with the highest drawn value, we instead go ahead and select that option and serve it to the user. That is all there is to it.
To make this clearer, lets take a look at an example. Below we have three options, each with their associated posterior distributions over their predicted conversion value. Thompson Sampling implicitly makes draws based on the probability that each is best by taking random draws from each of the three options, and then selecting the option with the highest valued draw.

Lets now take a random draw from the distributions of each option. Notice that even though ‘A’ has a higher predicted value (‘A’ is shifted to the right of the both ‘B’ and ‘C’), some of the left hand side of the distribution overlaps with the right hand sides of both ‘B’ and ‘C’. Since the width of the distribution indicates our uncertainty around the predicted value (the more uncertain, the wider the distribution), it isn’t inconceivable that either options B or C are the best.

In this case we see that our draw from ‘B’ happened to have the highest value (0.51 vs. 0.49 and 0.46). So we would select ‘B’ for this particular request.
This process is repeated with each selection request. If we were to get another request we might get draws such that ‘A’ was best.

Over repeated draws the frequency that each option is selected will be consistent with the probability that the option is the best one.

In our example we would select ‘A’ approximately 67% of the time, ‘B’ 8% of the time, and ‘C’ 25% of the time. Our roulette selection wheel looks like this:
As we collect more data we can update our distributions to reflect the information in the new data. For example, if as new data streams in, option ‘A’ continues to have higher conversion rates, then we would recreate our wheel to reflect this (note: warnings about confounding apply).
Where can I see these results in the Reporting?
What is neat is that Conductrics provides reporting and data visualizations based on data from your own experiments and adaptive projects.
If you head over to the audience report you will be see by default, both the predicted value of each option, but also, represented by the heights of the bars, the probability that the selection is best. For example, the report below shows that after 10,000 visitors, option ‘A’ has a predicted value of 4.96% and a 67% change to be a better option than both ‘B’ and ‘C’.

But wait, there is more. We even provide a data visualization view that displays the posterior distributions that Conductrics uses in the Thompson Sampling draws.

This is the same data as before, but with a slightly different view. Now, instead of the bar chart showing the chance that each option is the best, there are the actual distributions that are used to make the adaptive selections. This view can be useful to help understand why, even though an option has a higher predicted value than the others, it still won’t always be selected. The width of the distributions gives you an idea of the relative uncertainty in the data around the predicted values, and the greater degree of overlap indicates how much uncertainty there is between which option to select.
Adaptive Selection with Predictive Targeting
Conductrics also uses the same Thompson Sampling approach for targeting. When Conductrics determines that a user feature or trait is useful, it recalculates both the predicted values as well as the probabilities that each option is best. In the example below visitors on Apple Devices have a much higher predicted value under the ‘A’ option than either the ‘B’ or ‘C’ options. So much so that if Conductrics was to select options for users on Apple Devices, the ‘A’ option would always get selected.

However, for users not on Apple Devices, option ‘A’ performs much worse that either option ‘B’ or ‘C’, and hence, will not be selected (‘A’ Best-Pick Prob=0%).
You will notice that you still have access to the ‘Everyone’ audience, so that you can see how well each option performs overall, and what the overall probability of selection would be without any targeting.
If you would like, you can also see the visualization of the posterior distributions for each option, in each audience.

Now that you understand Thompson sampling, its obvious why for Apple Device users option ‘A’ has essentially a 100% chance of being selected. Even if we were to always pick pessimistically from the very left hand side (low value side) from option ‘A’, and always picked optimistically from the right hand side (high value side) from both ‘B’ and ‘C’, option ‘A’ would still, essentially, always have a higher value.
For visitors not on Apple Devices, the reverse is true. Even if we were to use the most optimistic draws from option ‘A’ and the most pessimistic draws from ‘B’ and ‘C’, option ‘A’ would still produce draws that were less than those from ‘B’ and ‘C’. As an aside, pruning out very poor options is often where much of the value of adaptive sections comes from.
If Thompson sampling and posterior distributions are tripping you up, you can also just think of it as Conductrics creating a different roulette wheel for each audience. When a member of that audience enters into an agent, Conductrics will first check which wheel to use, and then spin that wheel in order to make a selection for them. So based on the audience report for Apple and non Apple Device users, the logic would look like:

We can apply this logic to any number of audiences, such that there can be 10, 20, 100 etc. such audiences, each with their own custom roulette wheel.
In a way, when you peel back all of the clever machine learning, and multi-armed bandit logic, all Conductrics is doing is constructing these targeted roulette wheels, and using them to select experiences for your users.
One last thing: Uniform Selection
Even when the agent is set to make adaptive selection, there is still a portion of the traffic that is assigned by our fair roulette wheel. The reason for dong this is twofold:
- 1) To ensure a random baseline. In order to evaluate the efficacy of adaptive learning, it is important to ensure there is an unbiased comparison group to compare the results against.
- 2) To ensure that Conductrics still tries out all of the options in case there is some external change, or seasonality effect, that results in a change in the conversion rate/value of the decision options.
One last, last thing:
There are actually many different ways to tackle adaptive selection. Along with Thompson Sampling (TS), we have also used UCB methods, Boltzmann, simple e-greedy (those with sharp eyes will have noticed that what I have described in the post should be called an e-Thompson method), and even mixtures of them. In terms of performance, all of them are probably fine to use. We found that TS works better for us because it:
- uses similar ideas as Bayesian AB Testing, hence it is perhaps easier to understand by our clients than some of the other methods (“What, what?! What is this temperature parameter?”).
- fits gracefully with the approximate empirical Bayesian methods that Conductrics uses in its machine learning.
- is simple(ish) to implement.
So if you are using some other method, and it works, then great. Assuming you are paying attention to the possibility of non-stationary data and confounding, I am not convinced that for most use cases there is much extra juice to squeeze between one method or another.
‘* I actually don’t like gambling and am a total buzz kill at casinos.



